



音声認識の仕組みと課題丨音声をテキスト化する技術・アルゴリズムを解説|トラムシステム
人間が話した音声をAIが解析し、テキストに変換する技術を「音声認識」と呼びます。文字起こし、翻訳、機器操作の自動化などを実現するとして利用が拡大している一方で、システムの仕組みや活用方法について十分に理解が広がっていないのが現状です。
本記事では、音声認識技術の仕組み(アルゴリズム)や今後の課題について解説します。

目次
音声認識とは
音声認識とは、コンピューターが人間の発話をデジタルデータに変換し、それをもとにテキスト化を行う技術です。「これまで人間が行ってきた文字起こし作業をコンピューターが自動で行う」とイメージすると良いでしょう。
2010年代に飛躍的な発展を遂げた音声認識は現在も進化を続け、音声の文字変換だけに留まらず、人の言葉をある程度理解した上で、別の動作を行うレベルに到達しています。
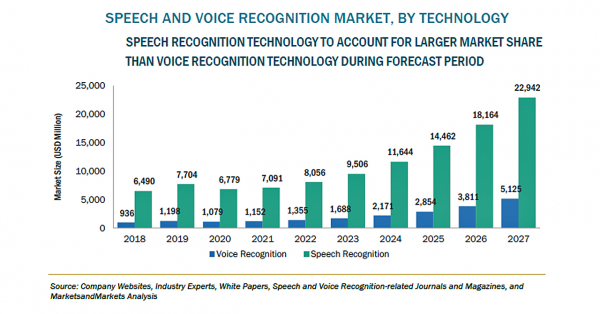
引用:https://www.dreamnews.jp/press/0000261934/
株式会社グローバルインフォメーションの調査によると、音声認識・言語認識の市場規模は2022年の94億ドルから年平均24.4%で成長を遂げ、2027年には281億ドルに達すると予想されています。音声認識技術は、もはや一大産業といえるでしょう。
音声認識の歴史
音声認識技術は約70年前から研究がスタートしているものの、コストパフォーマンスや精度に難があり、いくつかのサービスが発表されるに留まりました。音声認識の歴史を簡単に遡ってみましょう。
1950~60年代:音声認識黎明期
人間の発する声に関する研究が行われ、音声の特徴を分析して数値化する技術が誕生しました。1951年にアメリカのベル研究所が数字の1から9を認識可能な「Audery」を、1961年にアメリカのIBMが16単語を認識できる世界初の音声認識計算機「Shoebox」を発表しています。
1970~80年代:音声認識研究期
特筆すべき商品・サービスは発表されなかったものの、アメリカのDARPA(国防高等研究計画局)などで研究が進行しています。周波数特性の分析が進み、人間の音声をより単純な数式で表現可能となりました。有名なバーチャルアシスタント「Siri」の原型となる技術もこの時代に開発されています。
1990年代:音声認識実用期
日本で音声認識を利用した商品がいくつか開発され、カーナビやゲームなど身近な製品に搭載されました。特に任天堂の「ピカチュウげんきでちゅう」やセガの「シーマン」など音声認識でキャラクターと会話するゲームが流行しました。
2010年代:音声認識革命期
状況が劇的に変化したのは、2010年代に登場したディープラーニング技術の登場です。人間の脳回路を模したニューラルネットワークがデータの抽出や分析を自動で行うため、AIの学習スピードや精度が大幅に向上し、音声認識の本格的な実用化が可能となりました。
2011年にはアップルが世界初の実用的な音声アシスタント「Siri」を開発し、音声認識を搭載した商品開発が本格化します。特に2016年にAmazonから発売された「Amazon Echo」は記録的なヒットを遂げ、1100万台を売り上げました。
身近な音声認識技術の活用例
音声認識はすでに一般的なツールとなっており、以下のような商品が付加価値や市場価値を生み出しています。
音声アシスタント
AIがユーザーの音声を認識し、返答や動作を行うアプリケーションです。iPhoneに搭載される「Siri」やGoogle検索と連動する「Google Assistant」などが知られています。主にスマートフォンにインストールして利用します。
スマートスピーカー
音声アシスタントを搭載したスピーカーで、自宅でのニュース検索や家電操作を音声入力で実行します。「Amazon Echo」や「Google Home」が有名な商品です。近年は音楽再生や電子書籍の読み上げも可能となっており、日々の生活により浸透してきました。
文字起こしアプリ
時間のかかる作業だった文字起こしを代行してくれるアプリです。録音した音声を再生すれば自動で文字起こしが行われるため、手間と時間を大幅に軽減します。日本語対応では「Texter」や「スマート書記」が有名なサービスです。

そもそも「音声」とは
音声認識で用いられる「音声」とは「舌、唇、声帯など人間の調音機関を複雑に使用しながら発せられるもの」と定義されます。すなわち、音声認識で認識すべき音声は人間の話し声(音波)です。
特に複雑なことではないように思えますが、他人の話し声を自然と認識できる人間とは違い、機械にとっては難問です。人間の発する音声とそれ以外の音を正確に分類する必要があるだけでなく、性別、話し方の癖、言葉遣いといった人それぞれ違う要素も認識する必要があります。
音声認識の仕組み
ディープラーニングを用いた音声認識は構造が複雑で、数年で新しいモデルに更新されるため、理解するのに時間を要します。今回は初学者向けとして、従来行われてきたシンプルな音声認識の仕組みを紹介します。

1.音声録音
認識したい人の音声をマイクなどの入力装置で録音します。後の処理をスムーズに行うため、物音や認識したい人間以外の音声が入らない、静かな場所で録音するのが理想です。スマートフォンのマイク機能を活用することもできます。
2.音響分析
次に行うのが音響分析と呼ばれる作業です。まずはノイズや雑音を除去し、エラーが発生する確率を減らします。その後、録音された音声の周波数、強弱、音同士の間隔、時系列など様々な特徴を抽出し、コンピューターが認識しやすいように加工します。
3.音響モデル
音響分析によって加工された音声は、音響モデルと呼ばれる作業で解析されます。AIが事前学習したデータと照らし合わせ、音波の最小単位である音素を抜き出す作業です。音素は言語によって構成が異なり、日本語の場合は以下の3種類で構成されます。
・母音となる「あいうえお」
・撥音の「ん」
・子音23種類
「学校の近く」の場合は場合は「g-a-k-k-o-n-o-t-i-k-a-k-u」が音素に該当します。
4.パターンマッチ
音響モデルで抽出した音素「g-a-k-k-o-n-o-t-i-k-a-k-u」のままでは意味のある言葉ではないため、音素を意味のある単語に変換するパターンマッチと呼ばれる作業が必要です。パターンマッチでは以下のモデルが利用されます。
音声辞書
単語とその発音をセットで記録したモデルです。音声認識システムに学習させ、特定された音素とマッチングして単語に変換します。例えば「t-i-k-a-k-u」の音素は「知覚」「地殻」「近く」に変換可能です。
隠れマルコフモデル
日本語の文章を統計的に分析したモデルです。音声認識システムに学習させ、音素を単語の出現確率が高い組み合わせで文章化します。「g-a-k-k-o-n-o-t-i-k-a-k-u」の場合は「楽校の知覚」でも「學校の地殻」でもなく最も出現確率が高い「学校の近く」に変換可能です。
5.テキスト化
これらの過程を経て、最も自然な文章になる可能性が高いと判断された文字列がテキスト化されます。期待したような結果が出なかった場合は、調整や学習を繰り返してシステムを改修し、精度を高めていきましょう。

音声認識技術の課題と音声認識が日本で普及しづらい理由
日進月歩の発展を遂げる音声認識も、いまだ完璧とはいえません。また、日本は海外に比べて音声認識が普及しづらいと言われていることも、国内でのサービス普及が進まない原因と言われています。
音声認識技術の課題
2020年代の音声認識技術には以下のような課題が存在します。
・雑音や音割れの混入によって精度が低下する
・訛りなど学習データの少ない発音の認識が難しい
・「B」と「D」など発音が類似する単語の区別が難しい
・表記が複数存在する固有名詞への対応が難しい
これらはAIが自力で対処するのが難しい分野で、認識精度やユーザー満足度を低下させる原因となっています。AIはいまだ万能ではなく、人間の介在があってはじめて有益な音声認識になることを意識しなければなりません。
日本での音声認識技術の普及率は低め?
日本特有の課題として「音声認識の普及率が海外と比べて低い」があります。株式会社電通デジタルの2019年度調査では、スマートスピーカーの認知率が76%である一方、普及率はわずか5.9%に留まりました。
音声認識が日本で普及しづらい理由
音声認識が日本で普及しづらい理由として考えられるのは以下の3つです。
欧米との文化の違い
日本はアメリカとは違い、大声で自らの意見を主張するのを避け、言葉よりも文字によるコミュニケーションを好む傾向にあります。音声認識を利用したスマートスピーカーや音声アシスタントは日本人の趣向にマッチしておらず、敬遠されがちです。
英語と日本語の構造の違い
ひらがな、かたかな、漢字が入り混じる日本語は、英語よりも音声認識の難易度が高い言語です。同音異義語が多い、単語同士を明確に分かち書きしないなどの特徴が音声認識を妨げており、普及拡大にはさらなるブレークスルーが必要です。

まとめ
音声認識は信頼性に不安のあった時期を終え、その精度を急速に進化させつつあります。AIスピーカーや音声アシスタントシステムだけでなく、ロボットやAIとの対話でも役に立つでしょう。音声認識の概要を理解し、来るべき「音声認識時代」の到来に備えてください。

WRITER
トラムシステム(株)メディア編集担当 鈴木 康人
広告代理店にて、雑誌の編集、広告の営業、TV番組の制作、イベントの企画/運営と多岐に携わり、2017年よりトラムシステムに加わる。現在は、通信/音声は一からとなるが、だからこそ「よくわからない」の気持ちを理解して記事執筆を行う。



UNIVOICEが東京MXの「ええじゃないか」という番組に取り上げられました。






